Vos pipelines Snowflake ressemblent à ça ? Un CREATE TASK avec un SCHEDULE, un DELETE, un INSERT, un COMMIT — et quand ça plante à 3h du matin, c'est vous qui relancez manuellement.
Snowflake a lancé les Dynamic Tables en 2023. Ce n'est pas une évolution, c'est un changement de paradigme : du modèle impératif (vous écrivez le comment) au modèle déclaratif (vous définissez le quoi).
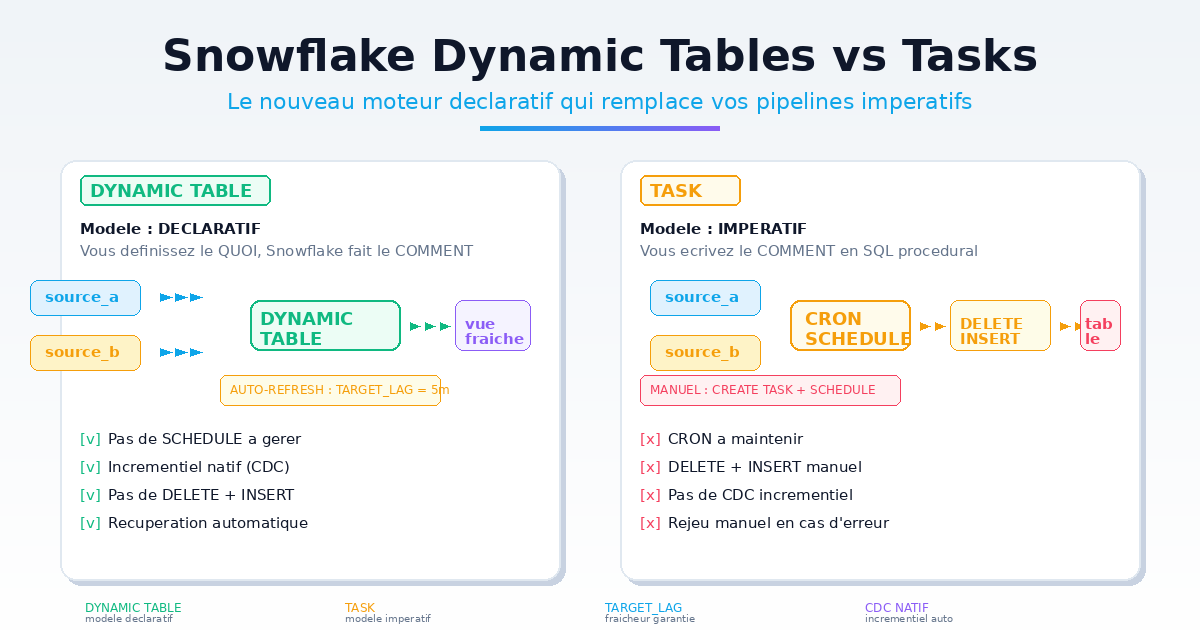
1. Le problème : le modèle impératif fatigue
Prenons un pipeline classique avec des Tasks :
-- Etape 1 : nettoyer
CREATE OR REPLACE TASK refresh_sales_summary
WAREHOUSE = 'ETL_WH'
SCHEDULE = 'USING CRON 0 */6 * * * UTC'
AS
DELETE FROM sales_summary WHERE snapshot_date = CURRENT_DATE();
INSERT INTO sales_summary
SELECT
region,
product_id,
SUM(amount) AS total,
CURRENT_DATE() AS snapshot_date
FROM raw_sales
WHERE order_date >= DATEADD(day, -30, CURRENT_DATE())
GROUP BY region, product_id;Ce qui va mal :
- Le CRON est statique : 6h, même si les données arrivent toutes les 5 minutes
- Le
DELETE + INSERTest atomique, mais pas incrémental : on réécrit 30 jours à chaque fois - Pas de gestion native du changement (CDC) : si une ligne source change, on ne le sait pas
- Le rejeu en cas d'erreur est manuel :
EXECUTE TASK refresh_sales_summary; - Le
WAREHOUSEest alloué en permanence, même quand le task ne tourne pas
2. Dynamic Tables : le modèle déclaratif
Une Dynamic Table est une vue matérialisée qui se rafraîchit automatiquement, avec un SLA de fraîcheur garanti.
CREATE OR REPLACE DYNAMIC TABLE sales_summary_dt
TARGET_LAG = '5 minutes'
WAREHOUSE = 'ETL_WH'
AS
SELECT
region,
product_id,
SUM(amount) AS total,
CURRENT_DATE() AS snapshot_date
FROM raw_sales
WHERE order_date >= DATEADD(day, -30, CURRENT_DATE())
GROUP BY region, product_id;Ce qui change :
TARGET_LAG = '5 minutes': Snowflake s'engage à ce que la table ne dépasse jamais 5 minutes de retard- Pas de
DELETE, pas d'INSERT, pas deSCHEDULE - Incrémental natif : Snowflake détecte les changements dans
raw_salesvia le Change Tracking (CDC) - Rejeu automatique : en cas d'erreur, Snowflake retry avec backoff exponentiel
3. Comparaison technique point par point
| Critère | TASK (impératif) | DYNAMIC TABLE (déclaratif) |
|---|---|---|
| Déclaration | CREATE TASK + SCHEDULE + SQL procédural |
CREATE DYNAMIC TABLE + TARGET_LAG + SELECT |
| Rafraîchissement | Basé sur le CRON (statique) | Basé sur le lag (dynamique, adaptatif) |
| Mode de mise à jour | Full refresh ou manuel | Incrémental natif (CDC) |
| Gestion des erreurs | Rejeu manuel (EXECUTE TASK) |
Retry automatique avec backoff |
| Fraîcheur garantie | Non (dépend du CRON) | Oui (TARGET_LAG) |
| Dépendances | AFTER clause (chaînement linéaire) |
Dépendances implicites via la requête SQL |
| Coût warehouse | Alloué en permanence | Payé uniquement au refresh |
| Surveillance | TASK_HISTORY, manuel |
DYNAMIC_TABLE_REFRESH_HISTORY, natif |
| Rollback | UNDROP TASK possible |
UNDROP DYNAMIC TABLE possible |
| Complexité JOIN | Gérable mais verbeuse | Identique, mais auto-optimisée |
4. Cas pratique 1 : pipeline simple de résumé journalier
Avant (Task)
CREATE TASK daily_sales_summary
SCHEDULE = 'USING CRON 0 6 * * * UTC'
AS
BEGIN
DELETE FROM daily_summary WHERE date = CURRENT_DATE();
INSERT INTO daily_summary
SELECT
CURRENT_DATE() AS date,
region,
COUNT(*) AS orders,
SUM(amount) AS revenue
FROM sales
WHERE order_date = CURRENT_DATE()
GROUP BY region;
END;Problèmes :
- Si
salesreçoit des données retardataires à 14h, le résumé de 6h est faux - Le
DELETEsupprime tout, même si une seule région a changé
Après (Dynamic Table)
CREATE DYNAMIC TABLE daily_summary_dt
TARGET_LAG = '1 hour'
WAREHOUSE = 'ETL_WH'
AS
SELECT
CURRENT_DATE() AS date,
region,
COUNT(*) AS orders,
SUM(amount) AS revenue
FROM sales
WHERE order_date = CURRENT_DATE()
GROUP BY region;Avantages :
- Si des données arrivent à 14h, la DT se rafraîchit dans l'heure (max)
- Incrémental : seules les lignes modifiées sont retraitées
5. Cas pratique 2 : pipeline multi-étapes avec dépendances
Avant (Tasks chaînées)
-- Etape 1 : staging
CREATE TASK staging_task
SCHEDULE = 'USING CRON 0 */4 * * * UTC'
AS INSERT INTO staging SELECT * FROM raw WHERE ...;
-- Etape 2 : transformation (dépend de staging)
CREATE TASK transform_task
AFTER staging_task
AS INSERT INTO transformed SELECT * FROM staging WHERE ...;
-- Etape 3 : agrégation (dépend de transform)
CREATE TASK agg_task
AFTER transform_task
AS INSERT INTO aggregated SELECT SUM(x) FROM transformed;Problèmes :
- Si
staging_taskéchoue,transform_tasketagg_taskne tournent pas — mais vous ne le savez que si vous surveillezTASK_HISTORY - Le chaînement
AFTERest séquentiel, pas parallélisable
Après (Dynamic Tables avec dépendances implicites)
-- Etape 1 : staging (Dynamic Table)
CREATE DYNAMIC TABLE staging_dt
TARGET_LAG = '10 minutes'
AS SELECT * FROM raw WHERE ...;
-- Etape 2 : transformation (référence staging_dt)
CREATE DYNAMIC TABLE transformed_dt
TARGET_LAG = '15 minutes'
AS SELECT * FROM staging_dt WHERE ...;
-- Etape 3 : agrégation (référence transformed_dt)
CREATE DYNAMIC TABLE aggregated_dt
TARGET_LAG = '20 minutes'
AS SELECT SUM(x) FROM transformed_dt;Magic : Snowflake comprend le graphe de dépendances via les requêtes FROM. Quand raw change, staging_dt se rafraîchit, ce qui déclenche transformed_dt, qui déclenche aggregated_dt. Le pipeline entier est auto-orchestré.
6. Les pièges de production
Le TARGET_LAG trop agressif
-- Catastrophe : warehouse constamment actif
CREATE DYNAMIC TABLE my_table
TARGET_LAG = '1 second' -- Trop !
WAREHOUSE = 'XSMALL';⚠️ Règle :
TARGET_LAGdoit être supérieur au temps de traitement réel. Commencez par'1 hour', mesurez, ajustez.
Les coûts warehouse non anticipés
Dynamic Tables ne facturent que le temps de refresh, mais :
- Un
TARGET_LAG = '1 minute'sur une table de 500M lignes = warehouse constamment chaud - Budget à surveiller via
WAREHOUSE_METERING_HISTORY
La fraîcheur vs la cohérence
-- Deux DT avec des lags différents
CREATE DYNAMIC TABLE table_a TARGET_LAG = '5 minutes' AS ...;
CREATE DYNAMIC TABLE table_b TARGET_LAG = '1 hour' AS SELECT * FROM table_a;table_b peut être 1h en retard par rapport à table_a, ce qui crée des incohérences temporelles dans les rapports. Alignez les TARGET_LAG des tables interdépendantes.
7. Performance : Task vs Dynamic Table
| Scénario | Task (full refresh) | Dynamic Table (incremental) |
|---|---|---|
| 10M lignes, aucune modif | 2m30 (scan total) | 0s (pas de refresh nécessaire) |
| 10M lignes, 1000 modifs | 2m30 (scan total) | 8s (CDC + merge) |
| 10M lignes, 5M modifs | 2m30 (scan total) | 1m45 (full refresh auto) |
Snowflake passe automatiquement en full refresh quand le taux de modification dépasse un seuil (~30%). Pas de configuration requise.
8. Quand garder les Tasks ?
Les Dynamic Tables ne remplacent pas tout. Gardez les Tasks quand :
| Cas d'usage | Pourquoi les Tasks restent pertinents |
|---|---|
| Appels externes | CALL external_function() ou API REST — les DT ne font que du SQL interne |
| Transactions complexes | Multi-statements avec BEGIN/COMMIT/ROLLBACK logique |
| Notifications | Envoi d'email/Slack après un traitement — CALL SYSTEM$SEND_EMAIL() |
| Archivage / purge | DELETE FROM ... WHERE date < X puis INSERT INTO archive |
| Orchestration externe | Vous utilisez déjà Airflow/dbt qui gère les dépendances |
9. Migration progressive : le guide pratique
Étape 1 : identifier les Tasks candidats
-- Lister les Tasks les plus gourmands
SELECT
name,
warehouse,
TIMESTAMPDIFF(second, scheduled_time, completed_time) AS duration_sec,
error_code
FROM SNOWFLAKE.ACCOUNT_USAGE.TASK_HISTORY
WHERE completed_time >= DATEADD(day, -7, CURRENT_TIMESTAMP())
ORDER BY duration_sec DESC;Étape 2 : créer la Dynamic Table en parallèle
-- Créer la DT sans impacter la Task existante
CREATE DYNAMIC TABLE sales_summary_new
TARGET_LAG = '1 hour'
WAREHOUSE = 'ETL_WH'
AS SELECT ...; -- copie de la logique de la TaskÉtape 3 : comparer les résultats
-- Vérifier que les données sont identiques
SELECT COUNT(*) FROM sales_summary
MINUS
SELECT COUNT(*) FROM sales_summary_new; -- Doit retourner 0Étape 4 : basculer les consommateurs
Redirigez vos dashboards/requêtes de sales_summary vers sales_summary_new, puis supprimez l'ancienne Task.
10. Checklist de production
| ✅ | Validation |
|---|---|
| ☐ | TARGET_LAG ≥ temps de traitement mesuré + 20% |
| ☐ | Monitoring : DYNAMIC_TABLE_REFRESH_HISTORY en place |
| ☐ | Budget : alerte sur WAREHOUSE_METERING_HISTORY |
| ☐ | Dépendances alignées : lag père < lag fils |
| ☐ | Test de charge : mesurer le temps de refresh sur 1M lignes |
| ☐ | Plan de rollback : UNDROP DYNAMIC TABLE testé |
| ☐ | Pas de Task critique orpheline : liste des Tasks non migrés |
Conclusion
Les Dynamic Tables ne sont pas un remplacement binaire des Tasks. C'est une nouvelle abstraction qui déplace la complexité de l'orchestration vers le moteur Snowflake.
- ✅ Pipelines simples : DT, sans hésiter
- ✅ Pipelines multi-étapes : DT avec dépendances implicites, nettement plus fiable
- ⚠️ Targets agressifs (
< 5 min) : vérifier le coût warehouse - ❌ Appels externes / procédures complexes : garder les Tasks
Le futur des pipelines Snowflake est déclaratif. Les Tasks deviendront l'exception, pas la règle.