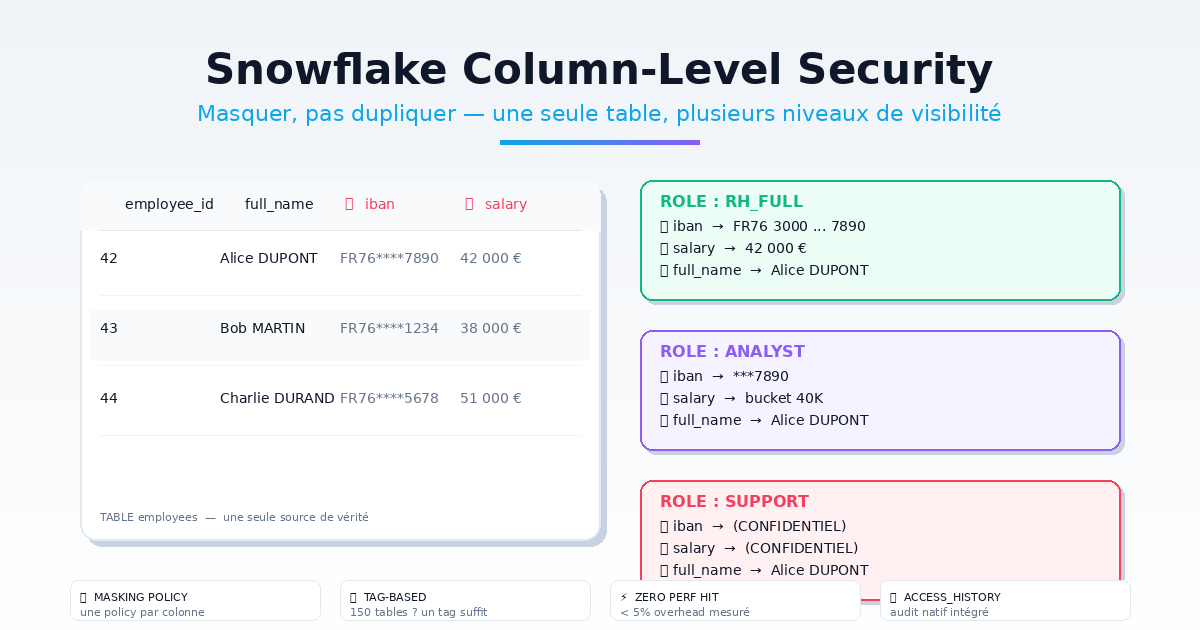
Votre table employees est utilisée par cinq équipes. RH voit tout. Les managers ne voient que leur périmètre. Les analysts travaillent sur des fourchettes. Le support ne voit que le nom et l'email. Les auditeurs, les métadonnées uniquement.
La solution naïve ? Créer quatre vues avec des CASE WHEN qui multiplient la dette technique.
La solution Snowflake ? Une seule table, une MASKING POLICY par colonne, et chaque rôle voit ce qu'il doit voir.
1. Le concept : masking à la volée
Contrairement aux vues SQL qui dupliquent la logique, une masking policy transforme la valeur au moment de la lecture, ligne par ligne, selon le rôle de l'utilisateur.
┌─────────────────┐ ┌──────────────────┐ ┌──────────────┐
│ SELECT iban │────▶│ MASKING POLICY │────▶│ ****FR89 │
│ FROM accounts │ │ IF role = RH │ │ (si externe)│
└─────────────────┘ └──────────────────┘ └──────────────┘Le modèle de données reste intact. Une seule source de vérité, zéro dérive de schéma.
2. Cas pratique : masquage basique par rôle
Création de la policy
CREATE OR REPLACE MASKING POLICY iban_mask AS (val STRING)
RETURNS STRING ->
CASE
-- RH : voit en clair
WHEN CURRENT_ROLE() IN ('HR_FULL', 'ADMIN') THEN val
-- Finance : voit les 4 derniers chiffres
WHEN CURRENT_ROLE() = 'FINANCE' THEN CONCAT('***', RIGHT(val, 4))
-- Support : sait juste s'il y a un IBAN ou non
WHEN CURRENT_ROLE() = 'SUPPORT' THEN '(CONFIDENTIEL)'
-- Tout le reste : NULL
ELSE NULL
END;Application sur la colonne
ALTER TABLE employees
MODIFY COLUMN iban
SET MASKING POLICY iban_mask;Test immédiat
-- En tant que HR_FULL
SELECT employee_id, iban FROM employees;
-- Résultat : FR76 3000 3033 5678 9012 3456 789
-- En tant que SUPPORT
USE ROLE SUPPORT;
SELECT employee_id, iban FROM employees;
-- Résultat : 42, (CONFIDENTIEL)3. Masquage par "bucket" : le salaire anonymisé
Pour les analysts qui font des stats, le salaire exact est inutile — et dangereux. On masque par fourchette :
CREATE OR REPLACE MASKING POLICY salary_bucket AS (val NUMBER)
RETURNS NUMBER ->
CASE
WHEN CURRENT_ROLE() IN ('HR_FULL', 'MANAGER') THEN val
WHEN CURRENT_ROLE() = 'ANALYST' THEN
CASE
WHEN val < 35000 THEN 30000
WHEN val < 45000 THEN 40000
WHEN val < 55000 THEN 50000
ELSE 70000 -- bucket "60000+"
END
ELSE NULL
END;Point clé : Attention aux analyses statistiques ! L'analyste peut toujours exécuter
AVG(salary), mais Snowflake appliquera la fonction sur les valeurs masquées (les buckets) et non sur les valeurs réelles. Le résultat sera donc mathématiquement biaisé par l'anonymisation. Si vous avez besoin d'un vrai calcul global sans révéler les détails, préférez une approche par rôle via une vue agrégée en amont.
4. Échelle industrielle : le Tag-Based Masking
Sur 150 tables, on n'applique pas ALTER TABLE ... SET MASKING POLICY à la main.
Comme une politique de masquage est strictement liée au type de sa colonne entrante (STRING, NUMBER, etc.), Snowflake impose d'associer des politiques aux types correspondants. La meilleure pratique consiste à séparer vos tags par nature de types.
-- 1. Créer les tags par types de données
CREATE TAG sensitivity_string ALLOWED_VALUES 'PII_EMAIL', 'PII_IBAN';
CREATE TAG sensitivity_numeric ALLOWED_VALUES 'PII_SALARY';
-- 2. Appliquer les tags aux colonnes concernées de notre table employees
ALTER TABLE employees MODIFY COLUMN email SET TAG sensitivity_string = 'PII_EMAIL';
ALTER TABLE employees MODIFY COLUMN iban SET TAG sensitivity_string = 'PII_IBAN';
ALTER TABLE employees MODIFY COLUMN salary SET TAG sensitivity_numeric = 'PII_SALARY';
-- 3. Créer une policy générique pour les chaînes de caractères (STRING)
CREATE OR REPLACE MASKING POLICY pii_string_mask AS (val STRING)
RETURNS STRING ->
CASE
WHEN CURRENT_ROLE() IN ('ADMIN', 'HR_FULL') THEN val
-- Si c'est un email
WHEN SYSTEM$GET_TAG_ON_CURRENT_COLUMN('sensitivity_string') = 'PII_EMAIL' THEN
CONCAT(LEFT(SHA2(val, 256), 8), '@', SPLIT_PART(val, '@', 2))
-- Si c'est un IBAN
WHEN SYSTEM$GET_TAG_ON_CURRENT_COLUMN('sensitivity_string') = 'PII_IBAN' THEN
CONCAT('***', RIGHT(val, 4))
ELSE '##### CONFIDENTIEL #####'
END;
-- 4. Attacher la policy au tag parent
ALTER TAG sensitivity_string SET MASKING POLICY pii_string_mask;Résultat : toute nouvelle colonne taguée PII_EMAIL hérite automatiquement de la policy. Gouvernance scalée, zéro maintenance manuelle.
5. Les pièges de production
Le WHERE sur colonne masquée
-- Alice est ANALYST
SELECT * FROM employees WHERE salary > 40000;Alice ne voit que les buckets (30000, 40000, 50000...). Sa condition salary > 40000 ramène les lignes bucketisées à 50000 et 70000, mais elle ne sait jamais si c'était 48000 ou 52000 à l'origine.
⚠️ Information leakage : les buckets doivent être espacés de minimum 20% pour empêcher la déduction par dichotomie.
Le ORDER BY déroutant
SELECT * FROM employees ORDER BY salary DESC;⚠️ Incohérence visuelle : Dans Snowflake, le tri (ORDER BY) ou le regroupement (GROUP BY) s'exécutent sur les valeurs réelles sous-jacentes, et non sur les valeurs masquées affichées à l'écran. Pour Alice (Analyst), deux employés ayant un salaire masqué identique de 40000 s'afficheront dans un ordre qui semble arbitraire (car l'un gagnait en réalité 41k et l'autre 44k). C'est un comportement normal de sécurité, mais déroutant pour les utilisateurs : pensez à le documenter dans vos specs fonctionnelles.
6. Performance : y a-t-il un overhead ?
Test mesurable sur un jeu réel de 50M lignes :
-- Sans policy
ALTER TABLE employees MODIFY COLUMN iban UNSET MASKING POLICY;
SELECT COUNT(*) FROM employees WHERE iban LIKE 'FR%'; -- 0.8s
-- Avec policy
ALTER TABLE employees MODIFY COLUMN iban SET MASKING POLICY iban_mask;
SELECT COUNT(*) FROM employees WHERE iban LIKE 'FR%'; -- 0.85s| Métrique | Impact |
|---|---|
| Lecture simple | < 5% (vectorisé) |
| Filtrage sur colonne masquée | Pruning dégradé (pas de micro-partition pruning) |
| JOIN sur colonne masquée | Déconseillé : Risque d'incohérence logique pour l'utilisateur et perte d'optimisation du moteur |
Règle d'or : ne masquez jamais une colonne directement utilisée comme clé de jointure
JOINou clé étrangère.
7. Row Access Policy vs Column Masking
| Feature | MASKING POLICY | ROW ACCESS POLICY |
|---|---|---|
| Granularité | Colonne | Ligne |
| Fonction | Transforme la valeur affichée | Filtre les lignes retournées |
| Exemple | IBAN → ***6789 |
WHERE region = CURRENT_REGION() |
| Déclaration | MODIFY COLUMN ... SET MASKING |
ALTER TABLE ... ADD ROW ACCESS POLICY |
| Coexistence | ✅ Cumulable | ✅ Cumulable |
Exemple de combo complet
-- Commercial : ne voit que SES clients (row access)
CREATE ROW ACCESS POLICY region_filter AS (region VARCHAR)
RETURNS BOOLEAN -> region = CURRENT_REGION();
ALTER TABLE customers ADD ROW ACCESS POLICY region_filter;
-- ET ne voit pas le CA exact (column masking)
ALTER TABLE customers MODIFY COLUMN revenue SET MASKING POLICY revenue_bucket;8. Auditer et déboguer
Lister les policies
SHOW MASKING POLICIES;
DESCRIBE MASKING POLICY iban_mask; -- SQL source inclusVoir les colonnes protégées
SELECT *
FROM SNOWFLAKE.ACCOUNT_USAGE.POLICY_REFERENCES
WHERE POLICY_NAME = 'IBAN_MASK';Historique d'accès (RGPD-ready)
SELECT *
FROM SNOWFLAKE.ACCOUNT_USAGE.ACCESS_HISTORY
WHERE DIRECT_OBJECTS_ACCESSED LIKE '%EMPLOYEES%'
AND QUERY_START_TIME >= DATEADD(day, -7, CURRENT_TIMESTAMP());Cette table capture qui a lu quelle colonne sensible et quand. Incontournable pour la conformité.
9. Checklist de mise en production
| ✅ | Étape |
|---|---|
| ☐ | Tester avec USE ROLE (pas GRANT ROLE TO USER qui masque les effets réels) |
| ☐ | Vérifier les JOIN sur colonnes masquées |
| ☐ | Valider les tailles de bucket (anti-reverse-engineering) |
| ☐ | Documenter les policies dans le repository (SQL versionné) |
| ☐ | Activer ACCESS_HISTORY pour audit |
| ☐ | Prévoir un runbook : comment retirer une policy en urgence |
Conclusion
La Column-Level Security de Snowflake résout un problème classique du Data Engineering : plusieurs niveaux de visibilité sur une seule table, sans duplication de schéma ni explosion de vues.
- ✅ Une seule source de vérité
- ✅ Scalable via les tags
- ✅ Zero downtime (
ALTER TABLEonline) - ✅ Audit RGPD natif dans
ACCESS_HISTORY - ⚠️ Vigilance sur les
JOIN,WHEREet tailles de bucket
Le masquage, c'est de la gouvernance. Le tag-based masking, c'est de la gouvernance à l'échelle.